PostgreSQL
PostgreSQL DB Stack
The PostgreSQL db stack is used to build and deploy PostgreSQL database in dataspaces and produce deployment-ready containers for the SCALE environment.
PostgreSQL (also referred to as Postgres) is an open-source relational database management system (RDBMS) emphasizing extensibility and standards compliance. It can handle workloads ranging from single-machine applications to Web services or data warehousing with many concurrent users.
The containers produced in this db stack share common requirements with other application and db stacks deployed to the SCALE environment. These shared requirements include:
- Security scanning for any vulnerabilities
- Staging of the db container in the appropriate Docker container repositories and tagged according to SCALE conventions
- Completion of Unit Testing and User Acceptance Testing
- Gated approvals before allowing deployments into pre-production and production environments
- Audit trail and history of deployment within the SCALE CI/CD Pipeline
Because of the above-listed requirements, the PostgreSQL db stack is provided in order to support the build and deployment of PostgreSQL database in a manner that integrates with SCALE requirements and processes. The flow of deployment includes first a Continuous Integration stage of processing in a pipeline prior to deployment in the Continuous Deployment stages. The Continuous Integration stage focuses on building the application, running scans to security vulnerabilities, and staging the container in the appropriate Docker repository ready for deployment. Subsequent pipeline stages deploy the application to the appropriate target Kubernetes spaces.
For details on getting started, repository structure, CI/CD pipelines, and pipeline definition, see the Common Database Documentation.
Configuration and Customization of the PostgreSQL Pipeline
Global Variables
For details on global variables, see Global Variables.
Database-Specific Pipeline Configuration
The extends YAML object is a complex object consisting of additional YAML objects. This object is used to extend the v4.3 pipeline logic (referenced by the repository defined in the resources object) by (a) referencing the correct dbstack pipeline entry point (dbaas/devexp-postgresql.yml@spaces for the PostgreSQL pipeline) and (b) passing a set of YAML objects as parameters to influence the behavior of the pipeline to meet an application teams specific needs.
The extends YAML object consists of 2 objects beneath it:
- template
- parameters
The template YAML object is a single value set to the initial entry point for the V4 pipeline for the PostgreSQL dbstack, so it should always be defined as follows:
variables:
- { group: postgresql-<dataspace repo name>.props }
resources:
repositories:
- { repository: templates, type: git, name: devexp-engg/automation, ref: release/v4.7 }
- { repository: spaces, type: git, name: spaces, ref: dbaas/v1.5 }
extends:
template: dbaas/postgresql-<dataspace repo name>.yml@spaces
The parameters YAML object is defined immediately following the template object and at the same indentation level. This is the object that requires the most attention and definition to be set up.
Pipeline Modes
For details on pipeline modes, see Pipeline Modes.
PostgreSQL pipelines also support the restoreFromSgrid parameter:
- { name: restoreFromSgrid, displayName: 'Restore from NPC Sgrid ?', type: 'string',values: ['yes','no'], default: 'no' }
Backup Schedule
For details on backup scheduling, see Backup Schedule.
Additional Configurations
Support for Kong
Support for Kong has been introduced since V4.7. Kong needs to be enabled in values.yaml and any override values files:
kong:
tls:
secret:
dbaas:
enabled: true
domain:
PLEASE NOTE: Ambassador and Kong both can not be enabled at once. You can select either but ONLY one at a time.
New file under helm template tcpingress.yaml is added to support Kong.
CPU Request Tuning
For details on CPU request tuning, see CPU Request Tuning.
PostgreSQL example:
extends:
parameters:
appVersion: <version>
postgresql:
podSpec:
cpuRequests: 200m
Database Configuration and Deployment
Database will be automatically configured with random password during provision. To modify the details of PostgreSQL passwords, you need to update <repo-name>.props variable group in pipeline library.
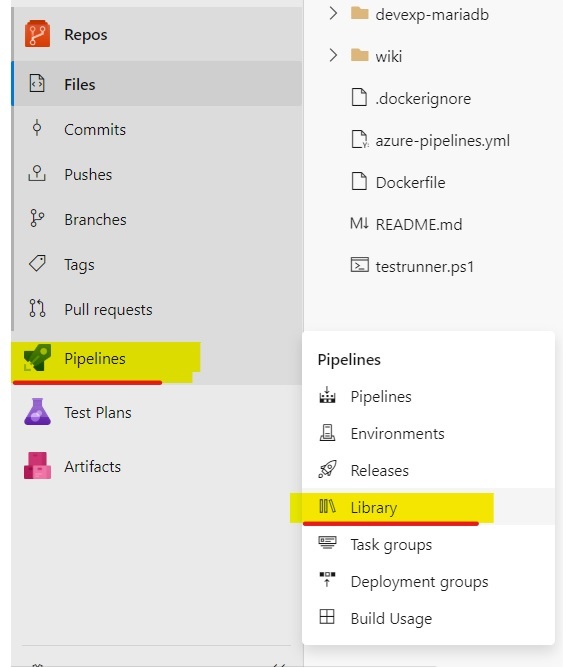
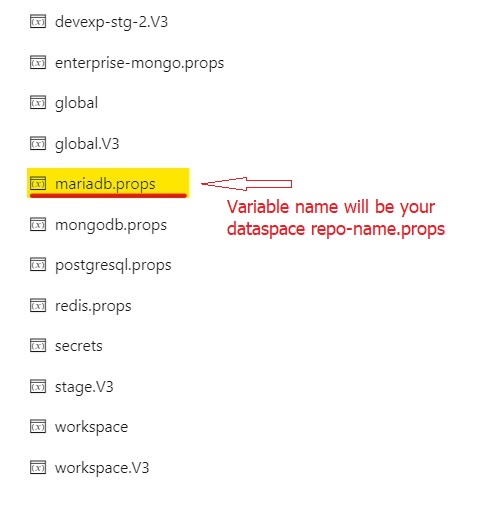
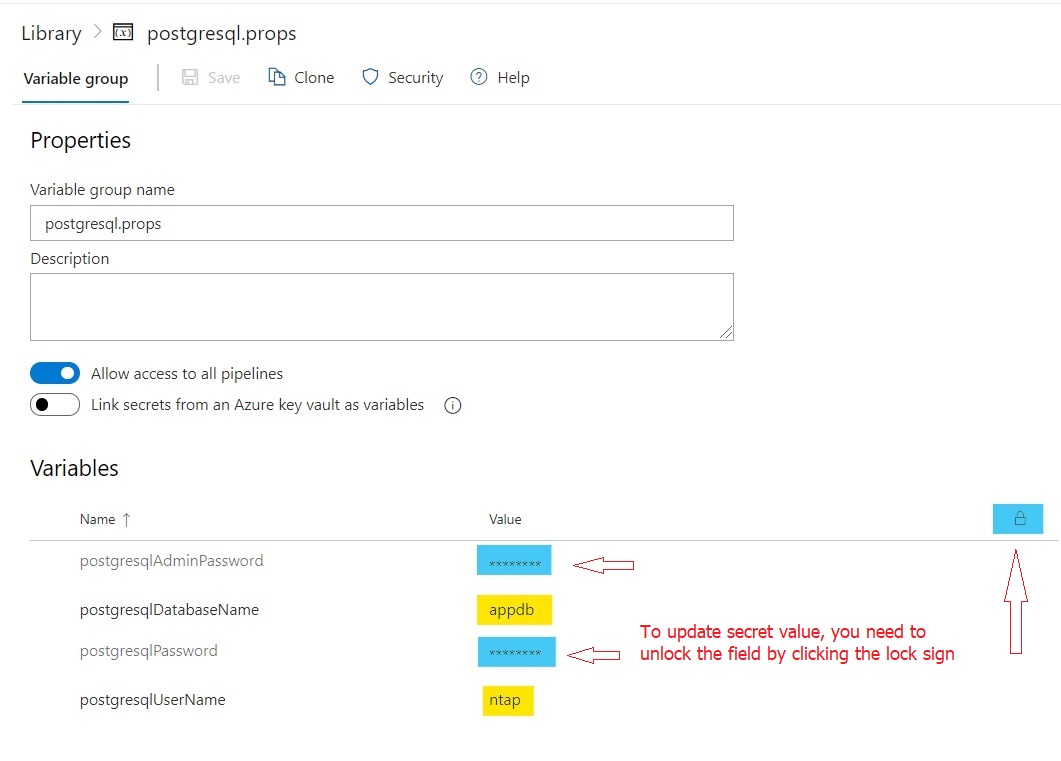
For general deployment configuration details, see Database Configuration and Deployment.
Helm Override Files
For details on helm override files, see Helm Override Files.
PostgreSQL example:
workspace:
helm:
overrideFiles: |
dbaas-postgres1/values.workspace.yaml
dataspace:
helm:
overrideValues: |
Changing Database User Password
For details on changing database user password, see Changing Database User Password.
Click the below image to watch the video
![]()
Exposing Databases Outside the Cluster
See our documention on SCALE Stunnel Client
Sysdig Monitoring
For details on Sysdig monitoring, see Sysdig Monitoring.
DR Changes
For details on DR changes, see DR Changes.
Detailed Pipeline Configuration
For details on pipeline configuration, see Detailed Pipeline Configuration.
Kubernetes Deployment Objects
For details on Kubernetes deployment objects, see Kubernetes Deployment Objects.
Troubleshooting
For troubleshooting information, see Troubleshooting.